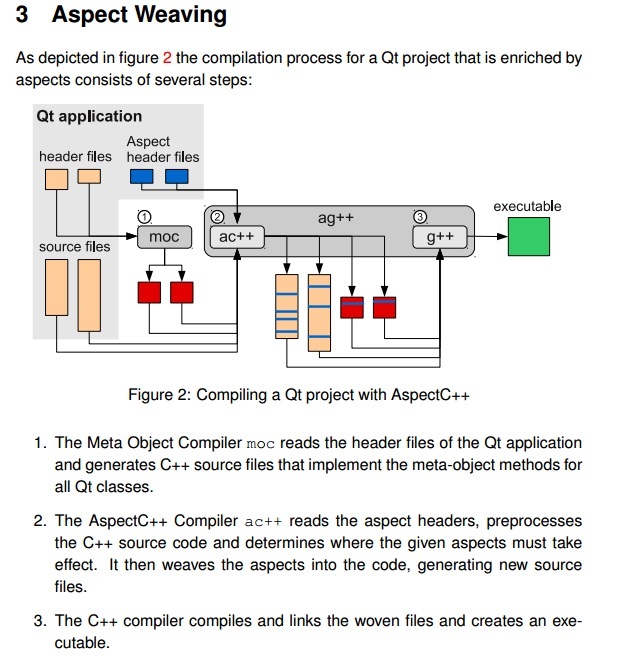
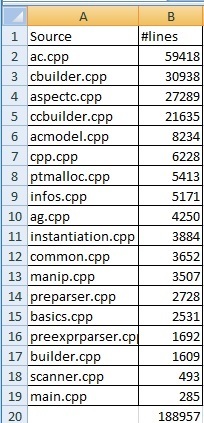
Een ppc?
Aha, een ppc is een portable personal computer? Aantal machines bij jou kwam daarmee op zes?
Dan ben je goed bezig, anderen moeten bij hun energiebedrijf aankloppen:
Gratis restwarmte

Start-up Nerdalize en duurzaam energiebedrijf Eneco breiden hun samenwerking uit met als doel een cloud te bouwen die Nederlandse huishoudens van duurzame restwarmte voorziet.
De cloud woont in dure datacenters en die vreten energie. Nerdalize heeft een product ontwikkeld waarmee de restwarmte van een cloudserver direct een gratis bijdrage kan leveren aan het warmte-systeem van een huis, zodat zowel huishoudens als professionele cloudgebruikers geld en energie besparen. De Nerdalize cloudgebruikers besparen al snel 50% op hun cloudkosten doordat ze niet langer betalen voor een gekoeld en duur datacenter.
Of het 28 januari is of 1 april:
Frequently Asked Questions about Nerdalize
• Can I really heat my home for free with your Heater?
Amazingly, yes! The Heater measures how much energy it uses to heat your home and you’ll get fully reimbursed for the cost of this energy. This means that with our Heater you’re heating your home for free!
• What type of internet connection do I need?
Currently we work with fibre optic connections.
• How much heat does the Nerdalize Heater generate?
Currently the Nerdalize Heater can produce 1 kw. And in the unlikely event that a user needs heat but the internet is down and the radiator has nothing to work on, it starts performing dummy equations.
• Will the Nerdalize Heater work during the summer?
Yes. Our Heater can expel excess heat to the outside when the homeowner does not require heating. This way we can compute at full capacity during winter and summer utilizing our hardware optimally.
• How are your Heaters physically secured?
Our Heaters are secured against tampering both in software and hardware. If tampering with the device is detected it will immediately halt operations and wipe its contents. We can also remote-wipe a Nerdalize Heater if there are signs of tampering.
Dat worden dus 25 van die Eneco eRadiatoren?
Capaciteit cv ketel berekenen voor een tussenwoning (slecht geïsoleerd):
7,00 x 5,00 x 2,50 x 85 = 7437 Watt (woonkamer)
2,00 x 1,00 x 2,50 x 70 = 350 Watt (hal voordeur)
1,50 x 1,00 x 2,50 x 70 = 262 Watt (wc)
3,00 x 2,50 x 2,50 x 77 = 1443 Watt (keuken)
2,00 x 1,00 x 2,50 x 70 = 350 Watt (hal achterdeur)
2,00 x 1,00 x 2,50 x 70 = 350 Watt (trap)
2,00 x 1,00 x 2,50 x 70 = 350 Watt (hal eerste verdieping)
3,00 x 2,80 x 2,50 x 93 = 1953 Watt (badkamer)
4,00 x 3,50 x 2,50 x 70 = 2450 Watt (slaapkamer 1)
4,00 x 3,50 x 2,50 x 70 = 2450 Watt (slaapkamer 2)
4,00 x 2,00 x 2,50 x 70 = 1400 Watt (slaapkamer 3)
18795 (totaal) x 1,15 (slecht geisoleerd) x 1,15 (extra capaciteit) : 1000 = 24.9 kW
Nerdalize zal toch wel op een jong en enthousiast Team leunen? Zeker en niemand heeft geen baard:
Aanbevolen verzorgingsproducten voor deze (stoppel-)baard:
• Tondeuse: Philips StyleXpert 9000
• Schaar: Tweezerman Spirit 2000 Styling
• Vochtinbrengende crème: Shiseido Men Hydrating Lotion
Nerds, dan weet je het wel, interne tegenspraak:


Green energy is the future
Readaar developed a smart way to analyze aerial imagery and LiDAR data (height information) in order to find different kinds of information on rooftops. The YES!Delft startup, Solar Monkey uses this data to design the best configuration for solar panel installations. A problem both companies run into is that the coordinates of the height information don’t match the coordinates of the aerial imagery. Readaar has built an algorithm to match the aerial imagery with the LiDAR data.
These algorithms are very compute intensive, thereby requiring vast amounts of computing power. Readaar was looking for a cloud provider for doing their analysis. Of course the well-known cloud computing platforms of Google and AWS are available to them, but instead they chose to use our servers. We offered a more affordable solution, but Readaar was especially charmed by our sustainable approach.