In dat geval, jij wilt verder met “hodoniemen”, straatnamen, ik deed daar iets te makkelijk over.
Bijvoorbeeld dat met die ‘suffix’, achtervoegsels, dat is wel een ding:
Veel straatnamen hebben de vorm van een samenstelling: bepalend element + grondwoord (Schipholweg, Steenstraat).
Ik had binnen de kortste keren 350 verschillende achtervoegsels verzameld die honderd- of duizendvoudig in de weg zaten als ik een schrijver uit een straatnaam probeerde te halen. In het genoemde “Wegvakken” komt “-straat” 244000 keer voor en “-weg” 185000 keer.
Anders dan ik vanwege de eenvoud liet zien, bij het isoleren van zo’n grondwoord, bijv. “straat” uit zo’n straatnaam moet ook gelet worden op de lengte van de string:
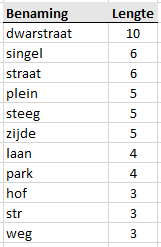
Loop ze in aflopende volgorde van aantal posities af bij het bepalen van de aanwezigheid van zo’n term, anders eindig je met “Eerste Bloemdwars” in plaats van het gewenste “Eerste Bloem”.
Gaat het zoals ik het deed ook goed als je van achteren komt bij hem van “De avonturen van Pinkeltje”? Ja:
openbareruimtenaam postcode woonplaats
Dick Laanplein 1521HT Wormerveer
Namen van andere overleden coryfeeën als Peter van Straaten en de Boudewijn Buchbrug, geen probleem.
Lijkt wel vergeefse moeite, uitdrukkelijk op naam-in-een-straatnaam zoeken, zonder het “straat”-deel?
Hier met behulp van ‘SimMetrics’ voor schrijver “Willem Frederik Hermans”, eerst met “straat”:
JaroWinklerSimilarity: Willem F. Hermansstraat (0,8990622)
LevensteinSimilarity: W Frederik Hermansstr (0,6521739)
MongeElkanSimilarity: W F Hermanszijde (1)
En dan zonder:
JaroWinklerSimilarity: Willem F. Hermansstraat (Willem F. Hermans, 0,9349105)
LevensteinSimilarity: W Frederik Hermansstr (W Frederik Hermans, 0,7826087)
MongeElkanSimilarity: W F Hermanszijde (W F Hermans, 1)
De uitkomst van de drie algoritmes verschilt onderling meer dan dat het “grondwoord” invloed lijkt te hebben.
Een van de ‘methods’ in deze ‘SimMetrics_Wrapper’ is ‘LevensteinSimilarity’. Levenstein?
For example, using the Levensthein distance between tweets to identify bots, aiming to classify bots quickly with minimum information.
Levensthein?
Levenstein - About 6,470 results (0.62 seconds)
Levensthein - About 2,710 results (0.49 seconds)
Google: Did you mean: “Levenshtein”?
Levenshtein - About 344,000 results (0.45 seconds)
Showing results for “Levenshtein distance”, demo:
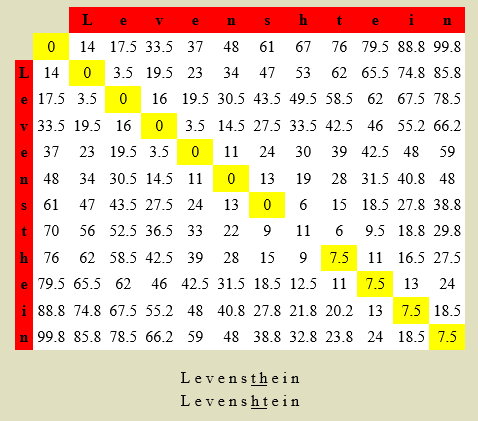
Uitleg en demonstratie bij www.let.rug.nl:
Levenshtein distance is obtained by finding the cheapest way to transform one string into another. Transformations are the one-step operations of (single-phone) insertion, deletion and substitution. In the simplest versions substitutions cost two units except when the source and target are identical, in which case the cost is zero. Insertions and deletions costs half that of substitutions.
Maar om terug te komen op het nut van straatnamen ontleden in “bepalend element” en “grondwoord”, het kan helpen bij het gebruik van weer andere methoden dan de drie bovengenoemde en die in de vorige post, LCS (longest common substring-search):
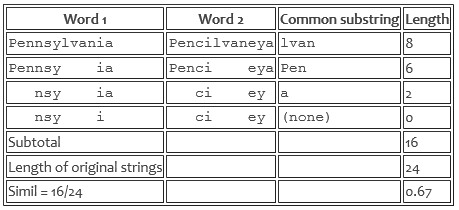
Op het terrein van ‘Inexact Pattern Matching’ wordt genoeg onderzoek gedaan naar geschikte principes:
String 1: W Frederik Hermansstr
String 2: Willem Frederik HermansThe results are then:
Levenshtein 65
Needleman-Wunch 74
Smith-Waterman 81
Smith-Waterman Gotoh 81
Smith-Waterman Gotoh Windowed Affine 81
Jaro 75
Jaro Winkler 78
QGrams Distance 67
Block Distance 33
Cosine Similarity 33
Euclidean Distance 18
Chapman Length Deviation 91
Overlap Coefficient 33
Net als bij “Levenshtein” ook hier woordblindheid onder professoren. Boven de pagina niet “Similarity” maar:
<title>String simularity</title>